This is an implementation of a quota engine, and the API routes to
manage its settings. This does *not* contain any enforcement code: this
is just the bedrock, the engine itself.
The goal of the engine is to be flexible and future proof: to be nimble
enough to build on it further, without having to rewrite large parts of
it.
It might feel a little more complicated than necessary, because the goal
was to be able to support scenarios only very few Forgejo instances
need, scenarios the vast majority of mostly smaller instances simply do
not care about. The goal is to support both big and small, and for that,
we need a solid, flexible foundation.
There are thee big parts to the engine: counting quota use, setting
limits, and evaluating whether the usage is within the limits. Sounds
simple on paper, less so in practice!
Quota counting
==============
Quota is counted based on repo ownership, whenever possible, because
repo owners are in ultimate control over the resources they use: they
can delete repos, attachments, everything, even if they don't *own*
those themselves. They can clean up, and will always have the permission
and access required to do so. Would we count quota based on the owning
user, that could lead to situations where a user is unable to free up
space, because they uploaded a big attachment to a repo that has been
taken private since. It's both more fair, and much safer to count quota
against repo owners.
This means that if user A uploads an attachment to an issue opened
against organization O, that will count towards the quota of
organization O, rather than user A.
One's quota usage stats can be queried using the `/user/quota` API
endpoint. To figure out what's eating into it, the
`/user/repos?order_by=size`, `/user/quota/attachments`,
`/user/quota/artifacts`, and `/user/quota/packages` endpoints should be
consulted. There's also `/user/quota/check?subject=<...>` to check
whether the signed-in user is within a particular quota limit.
Quotas are counted based on sizes stored in the database.
Setting quota limits
====================
There are different "subjects" one can limit usage for. At this time,
only size-based limits are implemented, which are:
- `size:all`: As the name would imply, the total size of everything
Forgejo tracks.
- `size:repos:all`: The total size of all repositories (not including
LFS).
- `size:repos:public`: The total size of all public repositories (not
including LFS).
- `size:repos:private`: The total size of all private repositories (not
including LFS).
- `sizeall`: The total size of all git data (including all
repositories, and LFS).
- `sizelfs`: The size of all git LFS data (either in private or
public repos).
- `size:assets:all`: The size of all assets tracked by Forgejo.
- `size:assets:attachments:all`: The size of all kinds of attachments
tracked by Forgejo.
- `size:assets:attachments:issues`: Size of all attachments attached to
issues, including issue comments.
- `size:assets:attachments:releases`: Size of all attachments attached
to releases. This does *not* include automatically generated archives.
- `size:assets:artifacts`: Size of all Action artifacts.
- `size:assets:packages:all`: Size of all Packages.
- `size:wiki`: Wiki size
Wiki size is currently not tracked, and the engine will always deem it
within quota.
These subjects are built into Rules, which set a limit on *all* subjects
within a rule. Thus, we can create a rule that says: "1Gb limit on all
release assets, all packages, and git LFS, combined". For a rule to
stand, the total sum of all subjects must be below the rule's limit.
Rules are in turn collected into groups. A group is just a name, and a
list of rules. For a group to stand, all of its rules must stand. Thus,
if we have a group with two rules, one that sets a combined 1Gb limit on
release assets, all packages, and git LFS, and another rule that sets a
256Mb limit on packages, if the user has 512Mb of packages, the group
will not stand, because the second rule deems it over quota. Similarly,
if the user has only 128Mb of packages, but 900Mb of release assets, the
group will not stand, because the combined size of packages and release
assets is over the 1Gb limit of the first rule.
Groups themselves are collected into Group Lists. A group list stands
when *any* of the groups within stand. This allows an administrator to
set conservative defaults, but then place select users into additional
groups that increase some aspect of their limits.
To top it off, it is possible to set the default quota groups a user
belongs to in `app.ini`. If there's no explicit assignment, the engine
will use the default groups. This makes it possible to avoid having to
assign each and every user a list of quota groups, and only those need
to be explicitly assigned who need a different set of groups than the
defaults.
If a user has any quota groups assigned to them, the default list will
not be considered for them.
The management APIs
===================
This commit contains the engine itself, its unit tests, and the quota
management APIs. It does not contain any enforcement.
The APIs are documented in-code, and in the swagger docs, and the
integration tests can serve as an example on how to use them.
Signed-off-by: Gergely Nagy <forgejo@gergo.csillger.hu>
When editing a user via the API, do not require setting `login_name` or
`source_id`: for local accounts, these do not matter. However, when
editing a non-local account, require *both*, as before.
Fixes#1861.
Signed-off-by: Gergely Nagy <forgejo@gergo.csillger.hu>
Follow #29522
Administrators should be able to set a user's email address even if the
email address is not in `EMAIL_DOMAIN_ALLOWLIST`
(cherry picked from commit 136dd99e86eea9c8bfe61b972a12b395655171e8)
Fix#27457
Administrators should be able to manually create any user even if the
user's email address is not in `EMAIL_DOMAIN_ALLOWLIST`.
(cherry picked from commit 4fd9c56ed09b31e2f6164a5f534a31c6624d0478)
Since `modules/context` has to depend on `models` and many other
packages, it should be moved from `modules/context` to
`services/context` according to design principles. There is no logic
code change on this PR, only move packages.
- Move `code.gitea.io/gitea/modules/context` to
`code.gitea.io/gitea/services/context`
- Move `code.gitea.io/gitea/modules/contexttest` to
`code.gitea.io/gitea/services/contexttest` because of depending on
context
- Move `code.gitea.io/gitea/modules/upload` to
`code.gitea.io/gitea/services/context/upload` because of depending on
context
(cherry picked from commit 29f149bd9f517225a3c9f1ca3fb0a7b5325af696)
Conflicts:
routers/api/packages/alpine/alpine.go
routers/api/v1/repo/issue_reaction.go
routers/install/install.go
routers/web/admin/config.go
routers/web/passkey.go
routers/web/repo/search.go
routers/web/repo/setting/default_branch.go
routers/web/user/home.go
routers/web/user/profile.go
tests/integration/editor_test.go
tests/integration/integration_test.go
tests/integration/mirror_push_test.go
trivial context conflicts
also modified all other occurrences in Forgejo specific files
Fixes#28660
Fixes an admin api bug related to `user.LoginSource`
Fixed `/user/emails` response not identical to GitHub api
This PR unifies the user update methods. The goal is to keep the logic
only at one place (having audit logs in mind). For example, do the
password checks only in one method not everywhere a password is updated.
After that PR is merged, the user creation should be next.
- Modify the `Password` field in `CreateUserOption` struct to remove the
`Required` tag
- Update the `v1_json.tmpl` template to include the `email` field and
remove the `password` field
---------
Signed-off-by: Bo-Yi Wu <appleboy.tw@gmail.com>
Part of #27065
This reduces the usage of `db.DefaultContext`. I think I've got enough
files for the first PR. When this is merged, I will continue working on
this.
Considering how many files this PR affect, I hope it won't take to long
to merge, so I don't end up in the merge conflict hell.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
This PR is a refactor at the beginning. And now it did 4 things.
- [x] Move renaming organizaiton and user logics into services layer and
merged as one function
- [x] Support rename a user capitalization only. For example, rename the
user from `Lunny` to `lunny`. We just need to change one table `user`
and others should not be touched.
- [x] Before this PR, some renaming were missed like `agit`
- [x] Fix bug the API reutrned from `http.StatusNoContent` to `http.StatusOK`
Partially for #24457
Major changes:
1. The old `signedUserNameStringPointerKey` is quite hacky, use
`ctx.Data[SignedUser]` instead
2. Move duplicate code from `Contexter` to `CommonTemplateContextData`
3. Remove incorrect copying&pasting code `ctx.Data["Err_Password"] =
true` in API handlers
4. Use one unique `RenderPanicErrorPage` for panic error page rendering
5. Move `stripSlashesMiddleware` to be the first middleware
6. Install global panic recovery handler, it works for both `install`
and `web`
7. Make `500.tmpl` only depend minimal template functions/variables,
avoid triggering new panics
Screenshot:
<details>
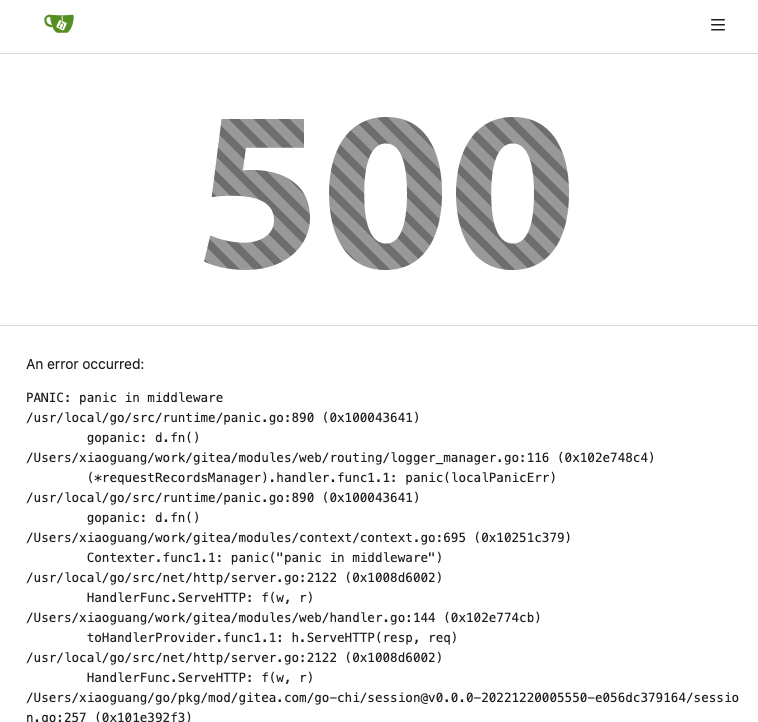
</details>
There was only one `IsRepositoryExist` function, it did: `has && isDir`
However it's not right, and it would cause 500 error when creating a new
repository if the dir exists.
Then, it was changed to `has || isDir`, it is still incorrect, it
affects the "adopt repo" logic.
To make the logic clear:
* IsRepositoryModelOrDirExist
* IsRepositoryModelExist
this is a simple endpoint that adds the ability to rename users to the
admin API.
Note: this is not in a mergeable state. It would be better if this was
handled by a PATCH/POST to the /api/v1/admin/users/{username} endpoint
and the username is modified.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Close#22934
In `/user/repos` API (and other APIs related to creating repos), user
can specify a readme template for auto init. At present, if the
specified template does not exist, a `500` will be returned . This PR
improved the logic and will return a `400` instead of `500`.
This PR refactors and improves the password hashing code within gitea
and makes it possible for server administrators to set the password
hashing parameters
In addition it takes the opportunity to adjust the settings for `pbkdf2`
in order to make the hashing a little stronger.
The majority of this work was inspired by PR #14751 and I would like to
thank @boppy for their work on this.
Thanks to @gusted for the suggestion to adjust the `pbkdf2` hashing
parameters.
Close#14751
---------
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Allow back-dating user creation via the `adminCreateUser` API operation.
`CreateUserOption` now has an optional field `created_at`, which can
contain a datetime-formatted string. If this field is present, the
user's `created_unix` database field will be updated to its value.
This is important for Blender's migration of users from Phabricator to
Gitea. There are many users, and the creation timestamp of their account
can give us some indication as to how long someone's been part of the
community.
The back-dating is done in a separate query that just updates the user's
`created_unix` field. This was the easiest and cleanest way I could
find, as in the initial `INSERT` query the field always is set to "now".
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
Change all license headers to comply with REUSE specification.
Fix#16132
Co-authored-by: flynnnnnnnnnn <flynnnnnnnnnn@github>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
* Apply DefaultUserIsRestricted in CreateUser
* Enforce system defaults in CreateUser
Allow for overwrites with CreateUserOverwriteOptions
* Fix compilation errors
* Add "restricted" option to create user command
* Add "restricted" option to create user admin api
* Respect default setting.Service.RegisterEmailConfirm and setting.Service.RegisterManualConfirm where needed
* Revert "Respect default setting.Service.RegisterEmailConfirm and setting.Service.RegisterManualConfirm where needed"
This reverts commit ee95d3e8dc9e9fff4fa66a5111e4d3930280e033.
This PR adds a middleware which sets a ContextUser (like GetUserByParams before) in a single place which can be used by other methods. For routes which represent a repo or org the respective middlewares set the field too.
Also fix a bug in modules/context/org.go during refactoring.
* Fix page and missing return on unadopted repos API
Page must be 1 if it's not specified and it should return after sending an internal server error.
* Allow ignore pages
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>

{kind=link}
{kind=link}